
01. 검색 시스템 이해하기
1.1 검색 시스템의 이해
1.1.1 검색 시스템이란?
사용자가 원하는 검색어에 대한 결과를 제공하는 서비스
검색 서비스 (Search Service) 는 검색 엔진을 기반으로 구축한 검색 시스템을 활용한 검색 결과를 서비스로 제공한다.
1.1.2 검색 시스템의 구성 요소
검색 시스템의 기본 구조는 개발사에 따라 다르지만 기본 구조는 거의 같다.
수집기
- 웹 사이트, 블로그, 카페 등 웹에서 정보를 수집하는 프로그램
- 크롤러 (Crawler), 스파이더 (Spider), 웜 (Warms), 웹 로봇 (Web Robots) 등으로 불리운다.
- 파일, 데이터베이스, 웹페이지등의 대부분의 정보가 수집 대상에 포함된다.
스토리지
- 데이터 베이스에서 데이터를 저장하는 물리적인 저장소
- 검색엔진은 색인한 데이터를 스토리지에 보관한다.
색인기
- 사용자 질의와 일치하는 정보를 찾기위해 의미있는 용어를 추출하고 검색에 유리한 역색인 구조로 데이터를 저장 한다.
검색기
- 사용자 질의를 입력받아 색인기에서 저장한 역색인 구조에서 일치하는 문서를 찾아 결과로 반환한다.
- 사용하는 형태소 분석기에 따라 검색 품질이 달라진다.
1.1.3 관계형 데이터베이스와의 차이점
관계형 데이터스와의 유사한점은 질의와 일치하는 데이터를 찾아 사용자에게 제공한다는 점이다.
검색 엔진과 데이터 베이스와 차이점
- 비정형 데이터 색인 및 검색 가능
- 형태소 분석을 통해 사람이 구사하는 자연어의 처리가 가능
- 역색인 구조를 바탕으로 빠른 검색 속도를 보장
엘라스틱에서 사용하는 용어와 관계형 데이터 베이스에서 사용하는 용어는 아래와 같은 차이점이 있다.
| Elastic Search | RDBMS |
|---|---|
| 인덱스 | 데이터베이스 |
| 샤드 | 파티션 |
| 타입 | 테이블 |
| 문서 | 행 |
| 필드 | 열 |
| 매핑 | 스키마 |
| Query DSL | SQL |
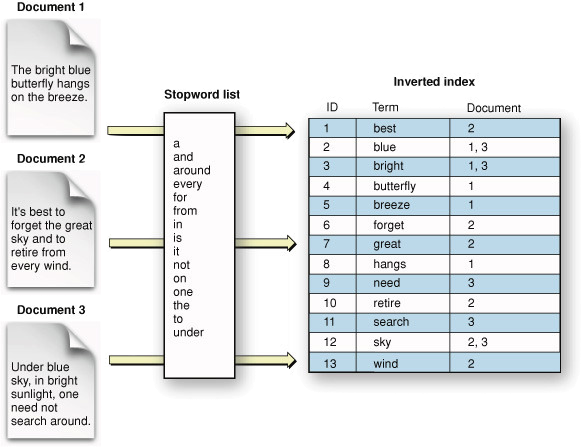
색인 (Index) & 역색인 (Inverted Index)
색인은 문서들에서 키워드를 뽑아내는 과정 역색인은 어떠한 키워드에 대해 요청이 들어왔을때 뽑아낸 키워드를 바탕으로 키워드가 포함된 문서를 찾아내는 과정
1.2 검색 시스템과 엘라스틱
1.2.1 엘라스틱서치가 강력한 이유
오픈소스 검색엔진
- 루씬 기반의 오픈소스 검색 엔진
- 2억 5천만건의 다운로드 횟수
전문 검색
- 기존 데이터 베이스의 기본적인 텍스트 검색 기능만 제공을 넘어선 고차원적인 전문검색 (Full Text) 을 지원
- 내용 전체를 색인해서 특정 단어가 포함된 문서를 검색하는 것
통계 분석
- 비정형 로그 데이터를 수직하고 한곳에 모아 통계 분석을 수행 가능하다.
- 엘라스틱 서치와 키바나를 연결하여 실시간으로 쌓이는 로그를 시각화하고 분석 가능하다.
스키마 리스
- 정형화 되어 있지 않는 다양한 형태의 문서도 자동으로 색인하고 검색 가능하다.
RESTful API
- HTTP 기반의 RESTful API 를 지원하고 Request 뿐만이 아니라 Response 에도 JSON 형식을 사용한다.
멀티 테넌시
- 서로 상이한 인덱스라도 검색할 필드명만 같으면 여러개의 인덱스를 한번에 조회가능한데 이를 이용하여 멀티테넌시 기능지원이 가능하다.
- 소프트웨어나 서비스를 여러 사람이 공유하여 사용할 수 있도록 서비스 해주는 것 (클라우드에서 많이 언급됨)
Document-Oriented
- 여러 계층의 JSON 형식의 구조화된 문서로 인덱스에 저장할 수 있다.
역색인 (Inverted Index)
- 엘라스틱의 가장 큰 장점으로 키워드를 바탕으로 문서를 찾아내는 방법이다.
확장성과 가용성
- 분산환경에서 데이터는 샤드 (Shard) 라는 작은 단위로 나뉘어 제공되며 인덱스를 만들때마다 샤드의 수를 조절할 수 있다.
- 데이터의 종류와 성격에 따라 분산하여 빠르게 처리 가능하다.
1.2.2 엘라스틱 서치의 약점
준 실시간 (Near Realtime)
- 색인된 데이터는 1초 뒤에나 검색이 가능하다.
트랜잭션 및 롤백 제공 불가
- 전체적인 클러스터의 성능 향상을 위함
데이터 업데이트 제공 안함
- 업데이트 명령이 요청될 경우 기존 문서를 삭제하고 변경된 내용으로 새로운 문서를 생성
- 불면젹 (Immutable) 이라는 이점을 취득
1.3 실습 환경 구축
1.3.1 엘라스틱서치 설치
자바 설치
- JDK 1.8 이상을 확인
$ java -version
엘라스틱 서치 설치
해당 문서 작성시 최신 버전 elasticsearch-7.6.0 으로 설치
엘라스틱 서치 실행과 중지
// 해당 폴더로 이동
$ cd elasticsearch-7.6.0/bin
// 엘라스틱 파일을 실행
$ ./elasticsearch
localhost:9020 경로로 진입하면 엘라스틱 서치의 클러스터 이름과 버전 정보가 노출
{
"name" : "MyungSeokui-MacBook-Pro.local",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "CjW9fYHLQOGkE6AEnp-PRg",
"version" : {
"number" : "7.6.0",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "7f634e9f44834fbc12724506cc1da681b0c3b1e3",
"build_date" : "2020-02-06T00:09:00.449973Z",
"build_snapshot" : false,
"lucene_version" : "8.4.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
포그라운드로 떠있으며 Ctrl + C 로 중단시키면 된다.
실습을 위한 엘라스틱서치 준비
교재에 있는 예제 인덱스 스냅샷 다운로드
$ wget https://github.com/javacafe-project/elastic-book-snapshot/raw/master/book_backup.zip --no-check-certificate
config/elasticsearch.yml 을 하기와 같이 수정해준다.
cluster.name: javacafe-cluster
node.name: javacafe-node1
network.host: 0.0.0.0
http.port: 9200
transport.tcp.port: 9300
node.master: true
node.data: true
path.repo: ["/Users/rrest/Downloads/book_backup/search_example", "/Users/rrest/Downloads/book_backup/agg_example"]
상기 설정에서 network.host: 0.0.0.0 은 제거해준다. (기동이 안됨)
이후 교재에 나온 스냅샷을 엘라스틱 서치로 인식
curl -XPUT 'http://localhost:9200/_snapshot/javacafe' -d '{
"type": "fs",
"settings": {
"location": "/Users/rrest/Downloads/book_backup/search_example",
"compress": true
}
}' -H 'Content-Type: application/json'
기존 교재 예시에서 -H 'Content-Type: application/json' 을 추가 (헤더가 별도로 필요함)
이후 생성된 아래 명령어를 통해 스냅샷을 확인
curl -X GET http://localhost:9200/_snapshot/javacafe/_all?pretty=true
두번째 스냅샷을 인식
curl -XPUT 'http://localhost:9200/_snapshot/javacafe' -d '{
"type": "fs",
"settings": {
"location": "/Users/rrest/Downloads/book_backup/agg_example",
"compress": true
}
}' -H 'Content-Type: application/json'
1.3.2 키바나 설치
키바나 다운로드 경로로 이동하여 키바나를 다운로드
이후 압축을 해제한 config/kibana.yml 에 다음 내용을 설정
elasticsearch.url: "http://localhost:9020"
교재에서는 위 설정으로 하라 했으나 동작이 되지 않아 하기 설정으로 세팅
elasticsearch.hosts: ["http://127.0.0.1:9200"]
정상적으로 키바나 기동이 완료되면 http://localhost:5601 경로로 접속
또한 키바나에서는 DEV_TOOLS 라는 도구를 통하여 문서의 매핑의 추가 삭제등의 작업을 JSON 포맷으로 요청 가능하다.
이는 http://localhost:5601/app/kibana#/dev_tools 경로로 접속
예시
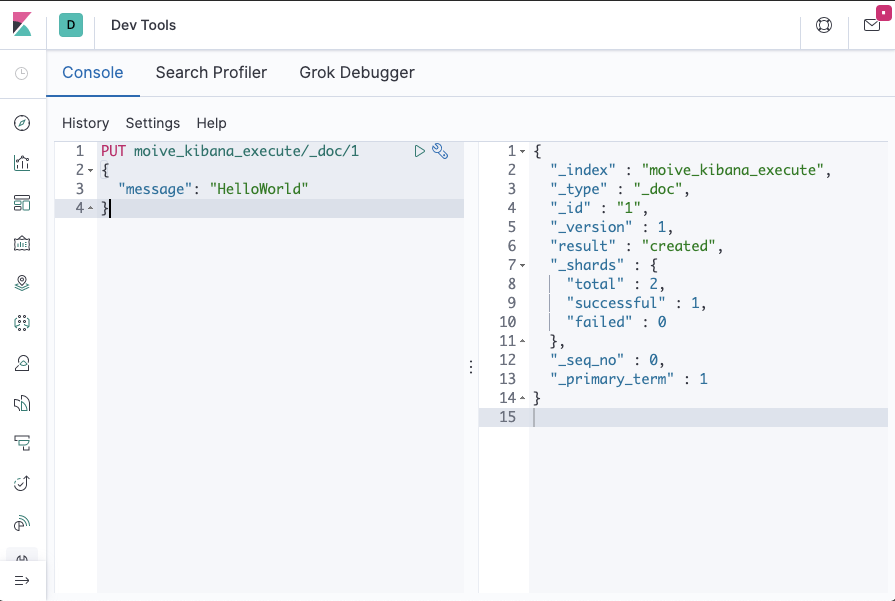
moive_kibana_execute 인덱스를 생성하여 문서를 색인해보자
PUT moive_kibana_execute/_doc/1
{
"message": "HelloWorld"
}
하기와 같이 등록
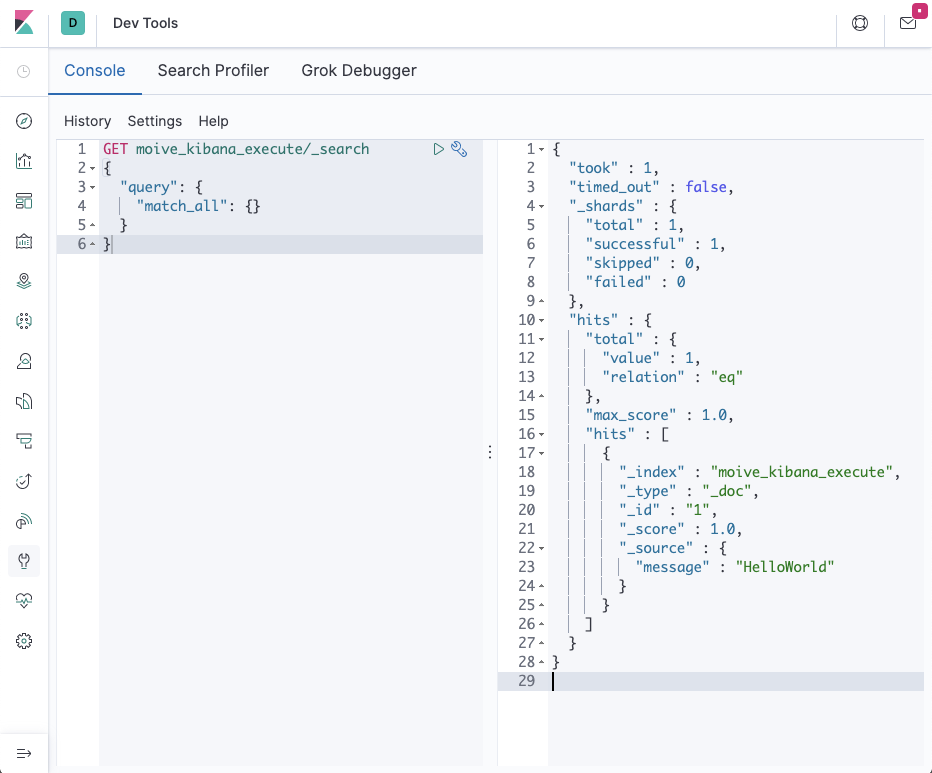
방금 생성한 문서를 검색
GET moive_kibana_execute/_search
{
"query": {
"match_all": {}
}
}
버전정보의 유의
Elastic Search 와 Kibana 의 버전을 통일시켜주는것이 좋다. 간혹 Kibana 의 동작이 불안정하여 기동이 안되는 경우가 빈번하다.