
Chapter 4 추상화 설계
추상화(abstraction) 는 프로그래밍 세계에서 가장 중요한 개념중 하나이다.
OOP(Object-Oriented Programming)에서 추상화는 세 가지 주요 개념중에 하나이다.
컴퓨터 과학에서 추상화(abstraction)는 복잡한 자료, 모듈, 시스템 등으로부터 핵심적인 개념 또는 기능을 간추려 내는 것을 말한다.
대표적인 예로 인터페이스가 있다.
인터페이스는 클래스라는 복잡한 것에서 메서드와 프로퍼티만 추출해서 간단하게 만들었으므로, 클래스의 추상화라고 할 수 있다.
추상화를 하려면 객체에서 무엇을 감추고 무엇을 노출해야 하는지를 결정해야 한다.
프로그래밍의 추상화
강력한 프로그래밍 언어들이 당연히 갖고 있는 기능 중 하나는 공통패턴에 이름을 붙여서 추상화를 만드는 기능이다.
예를 들면 함수, 델리게이트, 클래스가 대표적인 예이다.
추상화와 자동차
자동차는 잘 만들어진 인터페이스 이다.
내부적으로는 복잡한 요소들이 많지만, 굉장히 쉽게 사용할 수 있다.
내부적으로 일어나는 일을 마법처럼 숨겨줘서 운전자는 자동차의 내부 구성을 몰라도 운전자는 운전하는 방법만 알면 된다.
프로그래밍에서는 다음과 같은 목적으로 추상화를 사용한다.
- 복잡성을 숨기기 위해
- 코드를 체계화 하기 위해
- 만드는 사람에게 변화의 자유를 주기 위해
Item 26 함수 내부의 추상화 레벨을 통일하라
컴퓨터는 복잡한 장치이지만 이 복잡함이 여러 계층에 다양한 요소로서 분할되어 있어 쉽게 사용할 수 있다.
계층이 잘 분리되면 다른 계층은 이미 완성되어 있으므로 필요한 계층만 생각하면 된다.
개발자는 일반적으로 특정한 계층에서만 작업하며 가끔 추가로 계층을 올려서 사용한다.
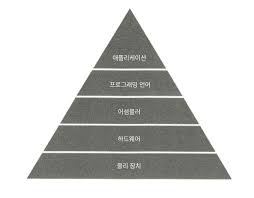
추상화 레벨
높은 레벨로 올라갈 수록 물리장치로부터 멀어진다.
높은 레벨일수록 걱정해야 하는 세부적인 내용들이 적다.
추상화 레벨 통일
컴퓨터 과학과 마찬가지로 코드도 추상화를 계층처럼 만들어서 사용할 수 있다.
이 역활을 하는 도구는 함수이며, 함수 또한 높은 레벨과 낮은 레벨을 구분해서 사용해야 한다는 원칙이 있다.
이를 추상화 레벨 통일 (Single Level of Abstraction, SLA) 이라고 부른다.
함수 내부에는 아래와 같이 여러 로직들을 구현할 수 있다.
class CoffeeMachine {
fun makeCoffee() {
// 수백 개의 변수를 선언합니다.
// 복잡한 로직을 처리합니다.
// 낮은 수준의 최적화도 여기서 잔뜩 합니다.
}
}
위와 같이 코드를 작성할 경우 makeCoffee 함수가 수백줄이 될 수 있어 다음과 같이 함수를 계층처럼 나누어서 사용하는 것이다.
class CoffeeMachine {
fun makeCoffee() {
boilWater()
brewCoffee()
pourCoffee()
pourMilk()
}
private fun boilWater() { /***/ }
private fun brewCoffee() { /***/ }
private fun pourCoffee() { /***/ }
private fun pourMilk() { /***/ }
}
위와 같이 함수를 계층으로 나뉘어서 사용하면 읽기 쉽고, 이해하기 쉽니다.
매우 간단한 추상화를 추출해서 가독성을 크게 향상시킨 것이다.
함수는 간단해야 한다. 이는 함수는 작아야 하며, 최소한의 책임만 가져야 한다는 일반적인 규칙이다.
추가적으로 이런 형태로 함수를 추출하면, 재사용과 테스트가 쉬워진다.
프로그램 아키텍처의 추상 레벨
추상화 계층이라는 개념은 함수보다 높은 레벨에서도 적용할 수 있다.
추상화를 구분하는 이유는 서브 시스템의 세부사항을 숨김으로써 상호 운영성(interoperability) 와 독립성을 얻기 위함이다.
모듈 시스템(modular system) 을 설계할 때도 중요하다.
모듈을 분리하면 계층 고유의 요소를 숨길수 있다.
계층이 잘 분리된 프로젝트는 좋은 프로젝트라고 부를수 있으며, 어떤 계층의 위치에서 코드를 보아도, 일반적인 관점을 얻을수 있다.
정리
별도의 추상화 계층을 만드는 것은 프로그래밍에서 일반적으로 사용되는 개념이다.
이는 knowledge 를 체계화 하고, 서브 시스템에서 세부 사항을 숨김으로 상호 운영성(interoperability)과 플랫폼 독립성을 얻게 한다.
함수, 클래스, 모듈 등으로 다양한 방식을 통해 추상화를 분리한다.
Item 27 변화로부터 코드를 보호하려면 추상화를 사용하라
물 위를 걷는 것과 명세서로 소프트웨어를 개발하는 것은 쉽다. 둘 다 동결되어 있다면...
함수와 클래스 등의 추상화로 실질적인 코드를 숨기면, 사용자가 세부 사항을 알지 못해도 괜찮다는 장점이 있다.
여러 추상화의 균형을 맞추는 방법을 알아본다.
상수
리터럴은 아무것도 설명하지 않는다. 따라서 코드에서 반복적으로 등장할 때 문제가 된다.
리터럴한 상수 프로퍼티로 변경하면 해당 값에 의미 있는 이름을 붙일 수 있으며, 상수 값을 변경해야 할 때 훨씬 쉽게 변경할 수 있다.
fun isPasswordValid(text: String): Boolean {
if (text.length < 7) return false
// ...
}
여기서 숫자 7 은 아마도 비밀번호의 최소 길이를 나타내겠지만, 이해하는데 시간이 걸린다.
상수로 빼낸다면 훨씬 쉽게 이해할 수 있을것이다.
const val MIN_PASSWORD_LENGTH = 7
fun isPasswordValid(text: String): Boolean {
if (text.length < MIN_PASSWORD_LENGTH) return false
// ...
}
이렇게 하면 비밀번호의 최소 길이를 변경하기도 쉽다.
이러한 숫자가 프로젝트 전체에 퍼져잇다면 변경하기 힘들것이다.
상수로 추출하면 다음과 같은 장점이 있다.
- 이름을 붙일 수 있다.
- 나중에 해당 값을 쉽게 변경할 수 있다.
함수
많이 사용되는 알고리즘은 다음과 같이 확장함수로 만들어서 사용할 수 있다.
fun Context.toast(
message: String,
duration: Int = Toast.LENGHT_LONG
) {
Toast.makeText(this, message, duration).show()
}
// 사용
context.toast(message)
// 액티비티 또는 컨텍스트의 서브클래스에서 사용할 경우
toast(message)
만약 토스트가 아니라 스낵바라는 다른 형태의 방식으로 출력해야 한다면 기존의 Context.toast() 를 Context.snackbar() 로 한꺼번에 수정하면 된다.
fun Context.snackbar(
message: String,
length: Int = Toast.LENGTH_LONG
) {
//...
}
하지만 이런 해결 방법은 좋지 않다.
함수의 이름을 바꾸는 것은 위험할 수 있다. 다른 모듈이 이 함수에 의존하고 있다면, 다른 모듈에 큰 문제가 발생할 것이다.
따라서, 메세지를 출력하는 더 추상적인 방법이 필요하다.
토스트 출력을 토스트라는 개념과 무관한 showMessage 라는 높은 레벨의 함수로 옮긴다.
fun Context.showMessage(
message: String,
duration: MessageLength = MessageLength.LONG
) {
val toastDuration = when(duration) {
SHORT -> Length.LENGTH_SHORT,
LONG -> Length.LENGTH_LONG
}
Toast.makeText(this, message, toastDuration).show()
}
enum class MessageLength { SHORT, LONG }
클래스
class MessageDisplay(val context: Context) {
fun show(
message: String,
duration: MessageLength = MessageLength.LONG
) {
val toastDuration = when(duration) {
SHORT -> Length.LENGTH_SHORT,
LONG -> Length.LENGTH_LONG
}
Toast.makeText(this, message, toastDuration)
.show()
}
}
enum class MessageLength { SHORT, LONG }
클래스가 함수보다 더 강력한 이유는 상태를 가질수 있므며, 많은 함수를 가질 수 있다는 점 때문이다(클래스 멤버 함수를 메서드라고 부른다).
클래스의 상태인 context는 기본 생성자를 통해 주입(inject)된다.
의존성 주입 프레임워크를 사용하면, 클래스 생성을 위임할 수 있다.
@Inject lateinit var messageDisplay: MessageDisplay
또한 mock 객체를 활용해서 해당 클래스에 의존하는 다른 클래스의 기능을 테스트할 수 있다.
val messageDisplay: MessageDisplay = mock()
게다가 메세지를 출력하는 더 다양한 종류의 메서드를 만들 수 있다.
messageDisplay.setCharistmasMode(true)
이처럼 클래스는 훨씬 더 많은 자유를 보장해 준다.
하지만 여전한 한계가 존재한다. 예를 들면 클래스가 final 이면, 해당 클래스 타입 아래에 어떤 구현이 있는지 알 수 있다.
open 클래스를 활용하면 서브 클래스를 활용하여 조금은 더 자유롭게 사용할 수 있다.
더 많은 자유를 얻으려면, 인터페이스 뒤에 클래스를 숨기는 방식으로 추상화 하면 된다.
인터페이스
코틀린 표준 라이브러리를 읽어보면, 거의 모든것이 인터페이스로 표현된다는 것을 확인할 수 있다.
인터페이스 뒤에 객체를 숨김으로써 실질적인 구현을 추상화하고, 사용자가 추상화된 것에만 의존하게 만들수 있는것 이다.
즉 결합(coupling)을 줄일수 있는 것이다.
코틀린이 클래스가 아니라 인터페이스를 리턴하는 이유는 코틀린은 멀티 플랫폼 언어이며, 각 플랫폼의 서로 다른 구현에 따른 리스트를 리턴해도 공통적인 인터페이스에 맞춰져 있으므로 차이없이 사용할 수 있다.
다음은 클래스를 인터페이스 뒤에 숨긴다는 것 은 다음 예시로 보여주고 있다.
interface MessageDisplay {
fun show(
message: String,
duration: MessageLength = LONG
)
}
class ToastDisplay(val context: Context): MessageDisplay {
override fun show(
message: String,
duration: MessageLength
) {
val toastDuration = when(duration) {
SHORT -> Length.SHORT
LONG -> Length.LONG
}
Toast.makeText(context, message, toastDuration)
.show()
}
}
enum class MessageLength { SHORT, LONG }
이렇게 구성하면 더 많은 자유를 얻을 수 있다.
이러한 클래스는 다른 플랫폼에서 공유하여 사용하는 공통 모듈에서도 MessageDisplay 를 사용할 수 있다.
val messageDisplay: MessageDisplay = TestMessageDisplay()
마지막으로 위와 같이 선언과 사용이 분리되어 있으므로, ToastDisplay 등의 실제 클래스를 자유롭게 변경할 수 있다.
다만 사용방법을 변경하려면, MessageDisplay 인터페이스를 변경하고, 이를 구현하는 모든 클래스를 변경해야 한다.
ID 만들기(nextId)
더 많은 추상화는 더 많은 자유를 주지만, 이를 정의하고, 사용하고, 이해하는 것이 어려워진다.
추상화가 주는 자유
추상화를 하는 몇가지 방법
- 상수로 추출한다.
- 동작을 함수로 래핑한다.
- 함수를 클래스로 래핑한다.
- 인터페이스 뒤에 클래스를 숨긴다.
- 보편적인 객체(universal object) 를 특수한 객체(specialistic object)로 래핑한다.
추상화를 할 때 사용하는 도구들
- 제네릭 타입 파라미터를 사용한다.
- 내부 클래스를 추출한다.
- 생성을 제한한다.
추상화의 문제
추상화도 비용이 발생하기 때문에 극단적으로 모든것을 추상화해서는 안된다.
FizzBuzzEnterpriseEdition
1부터 100까지를 출력하면서, 3의 배수일 때는 Fizz, 5의 배수일 때는 Buzz, 3과 5의 공배수일 경우에는 FizzBuzz를 출력하는 예제
추상화는 많은 것을 숨길수 있는 테크닉이다.
너무 많은 것을 숨기면 결과를 이해하는 것 자체가 어려워진다.
이해하기 어렵기 때문에 코드를 보기 무서워지고 더 나아가서는 읽기전에 두려움에 사로잡힐 수 있다.
어떻게 균형을 맞춰야 할까?
추상화는 자유를 주지만, 코드가 어떻게 돌아가는 것인지 이해하기 힘들다
추상화를 적용 여부는 프로젝트 혹은 팀에 따라 그 기준이 다르고 적절한 균형을 찾기 위해서는 많은 경험을 필요로 한다.
정리
추상화는 단순하게 중복성을 제거해서 코드를 구성하기 위함이 아니며, 코드를 변경해야 할 때 도움이 된다.
추상화를 사용해야 할 때 장점과 단점을 모두 이해하고, 프로젝트 내에서 그 균형을 찾아야 한다.
추상화가 너무 많거나 너무 적어도 좋은상황은 아니다.
Item 28 API 안정성을 확인하라
프로그래밍에서는 안정적이고 최대한 표준적인 API(Application Programming Interface)를 선호한다.
일반적으로 API 는 버전을 활용해서 라이브러리와 모듈의 안정성을 나타낸다.
많은 버저닝 시스템(versioning system) 이 있지만, 일반적으로는 시맨틱 버저닝(Semantic Versioning, SemVer) 을 선호한다.
- MAJOR 버전 : 호환되지 않는 수준의 API 변경
- MINOR 버전 : 이전 변경과 호환되는 기능을 추가
- PATCH 버전 : 간단한 버그 수정
만약 제공중인 API 가 안정적이지 않다면 Experimental 메타 어노테이션을 활용해서 경고 또는 오류를 할 수 있다.
@Experimental(level = Experimental.Level.WARNING)
annotation class ExperimentalNewApi
@ExperimentalNewApi
suspend fun getUser(): List<User> {
//...
}
안정적인 API의 일부를 변경해야 한다면, 전환하는데 시간을 두고 Deprecated 어노테이션을 활용해서 사용자에게 알려줘야 한다.
@Deprecated("Use suspending getUser instead")
fun getUsers(callback: (List<User>) -> Unit) {
//...
}
또한 직접적인 대안(direct alternative)이 있다면, IDE가 자동 전환할 수 있도록 ReplaceWith 을 붙여 주는것도 좋다.
@Deprecated("Use suspending getUser instead",
ReplaceWith("getUsers()"))
fun getUsers(callback: (List<User>) -> Unit) {
//...
}
정리
모듈과 라이브러리를 만드는 사람과 이를 사용하는 사람들간의 커뮤니케이션이 중요하다.
커뮤니케이션은 버전 이름, 문서, 어노테이션등을 통해 할 수 있다.
또한 안정적인 API에 변경을 가할 때는 사용자가 적응할 충분한 시간을 줘야 한다.
Item 29 외부 API를 랩(wrap)해서 사용하라
API 설계자가 안전하지 않다고 하거나, 우리가 그것을 신뢰하지 않는 경우 해당 API는 불안정하게 된다.
이러한 경우 API와 직접적으로 결합하지 않고 프로젝트 내부에서 해당 외부 라이브러리를 랩(wrap) 해서 사용하라
랩(wrap)해서 사용하면 다음과 같은 장단점을 얻을 수 있다.
- 장점
- 문제가 있다면 래퍼(wrapper)만 변경하면 되므로, API 변경에 쉽게 대응할 수 있다.
- 프로젝트 스타일에 맞춰서 API의 형태를 조정할 수 있다.
- 특정 라이브러리에서 문제가 발생하면, 래퍼를 수정해서 다른 라이브러리를 사용하도록 유연하게 코드를 변경할 수 있다.
- 필요한 경우 추가 동작이나 수정을 할 수 있다.
- 단점
- 래퍼를 따로 정의하는 비용이 든다.
- 다른 개발자가 프로젝트에 참여할 때, 어떤 래퍼들이 있는지 확인해야 한다.
- 외부 라이브러리에 의존하는 경우 직접적으로 문제 해결하기 쉽지 않다.
위와 같은 장점과 단점을 명확히 이해하고 래핑할 API 를 결정해야 한다.
따라서 신중하게 사용을 결정하고, 사용하기로 했다면 클래스와 함수로 랩하는 것을 고려하라.
Item 30 요소의 가시성을 최소화하라
클래스의 상태를 나타내는 프로퍼티를 외부에서 변경할 수 있다면, 클래스는 자신의 상태를 보장할 수 없다.
클래스의 상태를 마음대로 변경할 수 있다면, 클래스의 불변성(invariant)이 무너질 가능성이 있다.
class CounterSet<T>(
private val innerSet: MutableSet<T> = setOf()
): MutableSet<T> by innerSet {
var elementsAdded: Int = 0
private set
override fun add(element: T): Boolean {
elementsAdded++
return innerSet.add(element)
}
override fun addAll(elements: Collection<T>): Boolean {
elementsAdded += elements.size
return innerSet.addAdd(elements)
}
}
위 코드 처럼 elementsAdded 의 세터(setter)를 private로 설정했다.
이 부분 덕분에 외부에서 코드를 강제로 바꿀수 없고, 해당 프로퍼티에 신뢰성에도 문제가 없다.
이처럼 코틀린에서는 일반적으로 구체 접근자에 대한 가시성을 제한해서 모든 프로퍼티를 캡슐화 하는것이 좋다.
노출되면 안되는 프로퍼티가 노출되면 예상치 못한 변경에 의해 예외가 발생하고, 코드의 신뢰성이 떨어진다.
이는 동시성(concurrency)을 처리할 때 더 중요하다.
가시성 한정자 사용하기
내부적인 변경 없이 작은 인터페이스를 유지하고 싶다면, 가시성(visibility)를 제한하면 된다.
기본적으로 클래스와 요소를 외부에 노출할 필요가 없다면, 가시성을 제한해서 외부에서 접근할 수 없게 만드는 것이 좋다.
클래스 멤버의 경우 다음 4가지의 가시성 한정자 이용이 가능하다.
- public(기본): 어디에서나 볼 수 있다.
- private: 클래스 내부에서만 볼 수 있다.
- protected: 클래스와 서브클래스 내부에서만 볼 수 있다.
- internal: 모듈 내부에서만 볼 수 있다.
톱레벨 요소에서는 다음 세가지 가시성 한정자를 사용할 수 있다.
- public(기본): 어디에서나 볼 수 있다.
- private: 같은 파일 내부에서만 볼 수 있다.
- internal: 모듈 내부에서만 볼 수 있다.
정리
- 인터페이스가 작을 수록, 이를 학습하고 유지하는 것이 쉽다.
- 최대한 제한되어 있어야만 변경하기 쉽다.
- 클래스의 상태를 나타내는 프로퍼티가 노출되어 있다면, 클래스가 자신의 상태를 책임질 수 없다.
- 가시성이 제한되면 API 변경을 쉽게 추적할 수 있다.
Item 31 문서로 규약을 정의하라
일반적으로 대부분의 함수와 클래스는 이름만으로 예측할 수 없는 세부사항들을 가지고 있다.
명확하지 못한 함수명 혹은 파라미터로 발생 될 수 있는 문제들이 발생할 수 행위들은 문서로 설명하면 좋다.
타입 시스템과 예측
클래스가 어떤 동작을 할 것이라 예측되면, 서브클래스도 이를 보장해야 한다.
이를 리스코프 치환 원칙(Liskov Substitution Principle)이라고 부른다.
리스코프 치환원칙 (LSP: Liskov Substitution Principle)
S 가 T 의 서브타입이면 별도의 변경 없이도 T 타입의 객체를 S 타입으로 대체할 수 있어야 한다.
사용자가 클래스의 동작을 확실하게 예측할 수 있게 하려면, 공개 함수에 대한 규약을 잘 지정해야 한다.
정리
외부 API (external API) 를 구현할 때는 규약을 잘 정의해야 한다.
이러한 규약은 이름, 문서, 주석, 타입을 통해 구현할 수 있다.
규약은 사용자가 객체를 사용하는 방법을 쉽게 이해하는 등 요소를 쉽게 예측할 수 있게 해준다.
Item 32 추상화 규약을 지켜라
무언가를 할 수 있다는 것이 그것을 해도 좋다는 의미는 아니다.
리플렉션을 활용하여 코드를 열어 사용하는 것은 의도되지 않을수도 있기 때문이다.
규약은 보증(warranty)와 같다. 규약을 위반하면, 코드가 작동을 멈췄을때 문제가 된다.
상속된 규약
클래스를 상속하거나, 다른 라이브러리의 인터페이스를 구현할 때는 규약을 반드시 지켜야 한다.
다음과 같이 세트는 중복을 허용하지 않는데, equals가 제대로 구현되지 않아 중복을 허용해 버린다.
class Id(val id: Int) {
override fun equals(other: Any?) =
other is Id && other.id == id
}
정리
프로그램을 안정적으로 유지하고 싶다면 규약을 지켜라
규약을 깰 수 밖에 없다면, 이를 잘 문서화해서 안내하라