
Chapter 8 효율적인 컬렉션 처리
컬렉션은 프로그래밍에서 굉장히 중요한 개념이다.
현대의 프로그래밍 언어는 대부분 컬렉션 처리를 굉장히 잘 지원해 준다. 코틀린도 마찬가지로 굉장히 강력한 컬렉션 처리 방법을 제공한다.
val visibleNews = mutableListOf<News>()
for(n in news){
if(n.visible) {
visibleNews.add(n)
}
}
Collections.sort(visibleNews,{ n1, n2 -> n2.publishedAt - n1.publishedAt })
val newsItemAdapters = mutableListOf<NewsItemAdapter>()
for(ninvisibleNews){
newsItemAdapters.add(NewsItemAdapter(n))
}
위와 같이 장황한 코드를 다음과 같이 간결하게 작성 가능하다.
val newItemsAdapters = news
.filter { it.visibile }
.sortedByDescending { it.publishedAt }
.map(::NewsItemAdapter)
Item 49 하나 이상의 처리 단계를 가진 경우에는 시퀀스를 사용하라
많은 사람이 Iterable 과 Sequence 의 차이를 잊어버린다.
사실 거의 정의가 동일하므로 오해할 수 있다.
interface Iterable<out T> {
operator fun iterator() : Iterator<T>
}
interface Sequence<out T> {
operator fun iterator() : Iterator<T>
}
시퀀스는 처리 함수를 사용하면, 데코레이터 패턴으로 꾸며진 새로운 시퀀스가 리턴된다.
시퀀스는 toList 또는 count 등 최종 연산이 이루어질 때 수행되는 지연(lazy) 처리된다.
반면에 Iterable 은 처리함수를 사용할 때 마다 연산이 이루어져 List가 만들어진다.
public inline fun <T> Iterable<T>.filter(
predicate: (T) -> Boolean
): List<T> {
return filterTo(ArrayList<T>(), predicate)
}
public fun <T> Sequence<T>.filter(
predicate: (T) -> Boolean
): Sequence<T> {
return FilteringSequence(this, true, predicate)
}

시퀀스의 지연 처리는 다음과 같은 장점을 갖는다.
- 자연스러운 처리 순서를 유지한다.
- 최소한만 연산한다.
- 무한 시퀀스의 형태로 사용할 수 있다.
- 각각의 단계에서 컬렉션을 만들어 내지 않는다.
순서의 중요성
- 시퀀스 처리 : 요소 하나하나에 지정한 연산을 한꺼번에 적용한다. (element-by-element order, lazy order)
- 이터러블 처리 : 요소 전체를 대상으로 연산을 적용해 나간다. (step-by-step order, eager order)
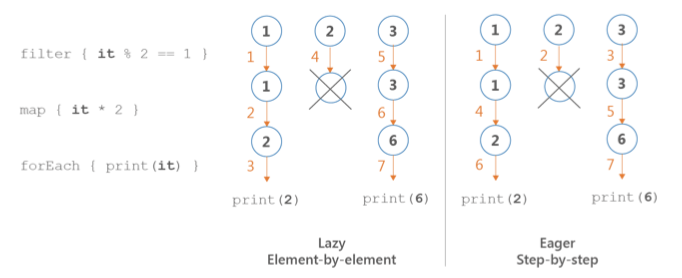
최소 연산
시퀀스에는 중간연산이라는 개념이 있어 앞의 10개에만 원하는 처리도 가능하다.
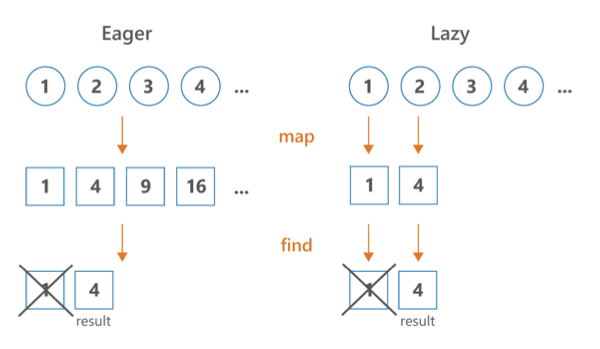
중간 처리단계를 모든 요소에 적용할 필요가 없는 경우에는 시퀀스를 사용하는 것이 좋다.
정리
컬렉션과 시퀀스는 같은 처리 메서드를 지원하며, 사용하는 형태가 거의 비슷하다.
결과적으로 무거운 객체나 규모가 큰 컬렉션을 여러 단계에서 처리할 때는 시퀀스를 사용하는 것이 좋다.
Kotlin Sequence Debugger 플러그인을 사용하면 각 처리 단계를 시각적으로 확인할 수 있다.
Item 50 컬렉션 처리 단계 수를 제한하라
모든 컬렉션 처리 메서드는 비용이 많이 든다.
표준 컬렉션 처리는 내부적으로 요소를 활용해 반복을 돌며, 내부적인 계산을 위해 추가적인 컬렉션을 만들어 사용하기도 한다.
어떤 메서드를 사용하느냐에 따라 컬렉션 처리의 단계수가 달라진다.
class Student(val name : String?)
// Works
fun List<Student>.getNames() : List<String> = this
.map { it.name }
.filter { it != null }
.map { it!! }
// Better
fun List<Student>.getNames():List<String> = this
.map { it.name }
.filterNotNull()
// Best
fun List<Student>.getNames():List<String> = this
.mapNotNull { it.name }
사실 컬렉션 처리와 관련해서 비효율적인 코드를 작성하는 이유는 어떤 메서드가 있는지 몰라서 그런경우가 많다.
| 원본 코드 | 대체 코드 |
|---|---|
| .filter { it != null} .map { it!! } | .filterNotNull() |
| .map { <Transformation> } .filterNotnull() | .mapNotNull { <Transformation> } |
| .map { <Transformation> } .joinToString() | .joinToString { <Transformation> } |
| .filter { <Predicate1> } .filter { <Predicate2> } | .filter { <Predicate1> && <Predicate2> } } |
| .filter { it is Type } .map { it as Type } | .filterIsInstance<Type>() |
| .sortedBy { <Key2> } .sortedBy { <Key1> } | .sortedWith( compareBy( { <Key1> }, { <Key2> } ) ) |
| listOf(...) .filterNotNull() | listOfNotNull(...) |
| .widthIndex() .filter { (index, elem) -> <Predicate using index> } .map { it.value } | .filterIndexed{ index, elem -> <Predicate using index> } (map, forEach, reduce, fold 도 비슷하다.) |
정리
대부분의 컬렉션 처리 단계는 전체 컬렉션에 대한 반복 과 중간 컬렉션 생성 이라는 비용이 발생한다.
Item 51 성능이 중요한 부분에서 기본 자료형 배열을 사용하라
코틀린은 기본 자료형(primitive) 를 선언할 수 없지만, 최적화를 위해 내부적으로는 사용할 수 있다.
기본 자료형이 가진 특성은 다음과 같다.
- 가볍다 : 일반적인 객체와 다르게 추가저긍로 포함되는 것들이 없기 때문이다.
- 빠르다 : 값에 접근할 때 추가적인 비용이 들지 않는다.
대규모의 데이터를 처리할 때 기본 자료형을 사용하면, 상당히 큰 최적화가 이루어진다.
하지만 코틀린에서 사용되는 List와 Set등의 컬렉션은 제네릭 타입이다.
제네릭 타입에는 기본 자료형을 사용할 수 없으므로, 래핑된 타입을 사용해야 한다.
일반적인 경우에는 이렇게 하는것이 더 처리가 쉬워지므로 적합하다.
하지만 성능이 중요한 경우라면 IntArray 와 LongArray 등의 기본 자료형을 활용하여 배열을 사용하는것이 좋다.
배열은 더 적은 메모리를 차지하고, 더 빠르게 동작하지만 일반적인 경우에는 List 를 사용하는것이 좋다.
List 에는 다양한 편의기능이 내장되어 있으며, 더 많은 곳이 더 쉽게 사용이 가능하기 때문이다. (성능이 중요한 경우에는 Array)
정리
일반적으로 Array 보다 List 와 Set 을 사용하는 것이 좋다.
하지만 기본 자료형의 컬렉션을 굉장히 많이 보유해야 하는 경우에는 성능을 높이고, 메모리 사용량을 줄일 수 있도록 Array 를 사용하는 것이 좋다.
Item 52 mutable 컬렉션 사용을 고려하라
immutable 컬렉션보다 mutable 컬렉션이 더 좋은점은 성능적인 측면에서 더 빠르다는 것이다.
immutable 컬렉션에 원소를 하나 더할 때, 새로운 컬렉션을 만들면서 여기에 요소를 추가해야 한다.
operator fun <T> Iterable<T>.plus(element: T) : List<T> {
if (this is Collection) return this.plus(element)
val result = ArrayList<T>()
result.addAll(this)
result.add(element)
return result
}
위와 같이 컬렉션을 복제하는 처리는 비용이 많이 드는 작업이다.
그래서 이러한 복제 처리를 하지 않는 mutable 컬렉션이 성능적인 관점에서는 좋다.
immutable 컬렉션이 더 안전할 수 있지만 일반적인 지역변수는 동기화나 캡슐화 문제에 포함되지 않는 경우가 대부분이다.
때문에 일부 제한적인 경우를 제외하고는 mutable 컬렉션을 사용하는것이 더 합리적일 수도 있다.
일부 표준 라이브러리에서는 내부적으로 어떤 처리를 할 때는 mutable 컬렉션을 사용하도록 구현되어 있다.
inline fun <T, R> Iterable<T>.map(
transform: (T) -> R
): List<R> {
val size = if (this is Collection<*>) this.size else 10
val destination = ArrayList<R>(size)
for (item in this)
destination.add(transform(item))
return destination
}
정리
가변 컬렉션은 일반적으로 추가 처리가 빠르다.
immutable 컬렉션은 컬렉션 변경과 관련된 처리를 더 세부적으로 조정할 수 있다.
일반적으로 지역 스코프에서는 이러한 세부적인 조정이 필요하지 않으프로 가변 컬렉션을 사용하는 것이 더 좋을수 있다.
특히 유틸성 요소에서는 요소 삽입이 자주 발생할 수 있기 때문이다.